基于Yjs实现的多人协同编辑应用实践
基于Yjs实现的多人协同编辑应用实践
前言
远程协同在大家生活中多多少少都是有接触过的,包括但不限于腾讯文档,金山文档等,他们都有多人在线协同编辑的能力。其主要围绕的都是一个 “多人实时编辑”, 在没有多人协同编辑的过去,假如一份文档需要多个人来完成,要么是按顺序每个人写一点,上面一个人写完了发给下一个人继续完成,要么就是所有人自己写自己的,然后最后统一发给一个人整合成一份文档。这样效率多少都有点低。远程协同正是为了解决这一个问题而诞生的,他做到了一份文档每个人都能同时写自己的一部分,同时展现整体效果的功能。
本文不会着重探讨 Yjs 背后的底层原理,而更关注于项目的技术栈与架构流程演变,如果您对 Yjs 及其背后的 CRTD 协同算法有兴趣可以移步文章: 基于CRDT的协同编辑开发
项目背景
起因是个人自身的一个项目,他有这样一个词条编辑功能,其基于 Markdown,可扩展为 MDX,是纯文本编辑应用。当这个词条正在被一个人编辑时,其他人不可进入该词条房间,直到前一个人退出房间才可继续。
有时候写词条会有多个人,两个人要想写同一个词条或者对另一个人写词条做指导时是完全没法实现的,为了解决这个问题,接下来就是开始了技术调研与方案选择。
解决方案选择
经过调研后,总结出来的选择如下:
- 开放观看编辑操作,这个可以实现平台内小部分指导编写词条功能
- 开放每个人的编辑,每个人编辑完成点击保存时服务端进行一次类似 git diff 合并操作,假如发生冲突则反馈到用户端,让用户自行处理
- 通过远程协同技术实现多人同时编辑
三个解决的问题和新产生的问题如下:
- 观看编辑操作满足了一小部分可以通过语音沟通进行编辑的词条,但是其本质上并没有解决多人同时编辑的问题
- 开放每个人的编辑操作则解决了不能多人同时编辑的问题,但是新产生的问题如下:
- 假如两个人发生了并行编辑,其中一个人编写了大量内容,另一个人同样编写了大量内容,两份文档提交到服务端后势必会有大面积冲突,虽然这个问题在本应用下问题不是很大,因为是纯文本编辑,但是在富文本以及 excel 场景下用户解决的成本将会变得特别高
- 当两个人编写的内容发生了穿插(每个段落中都有类似的文字)时,用户 diff 的成本将会随着内容的变化呈现线性提升
- 远程协同解决了多人编辑 + 实时展示的问题,但他同样也有一些问题:
- 个人并没有远程协同技术落地实践的经验,算是第一次接触
- 服务端实现是基于 websocket,需要具备这部分的编程能力
最后经过斟酌个人还是选择了实现远程协同这个方案,这也算是个人对技术能力的一次实践与提升。当然假如这是一个大型项目,我肯定会找研发团队参与进来进行彻底的研究,或者选择 diff 作为解决方案,因为本应用是纯文本;假如时间不够的话我会选择直接在操作平台内嵌腾讯文档,毕竟现成的可以直接拿来用,当然也要承担一部分第三方应用的风险就是了。
经过长时间的探索与实践,现上线版本的一个协同编辑的页面展示如下:
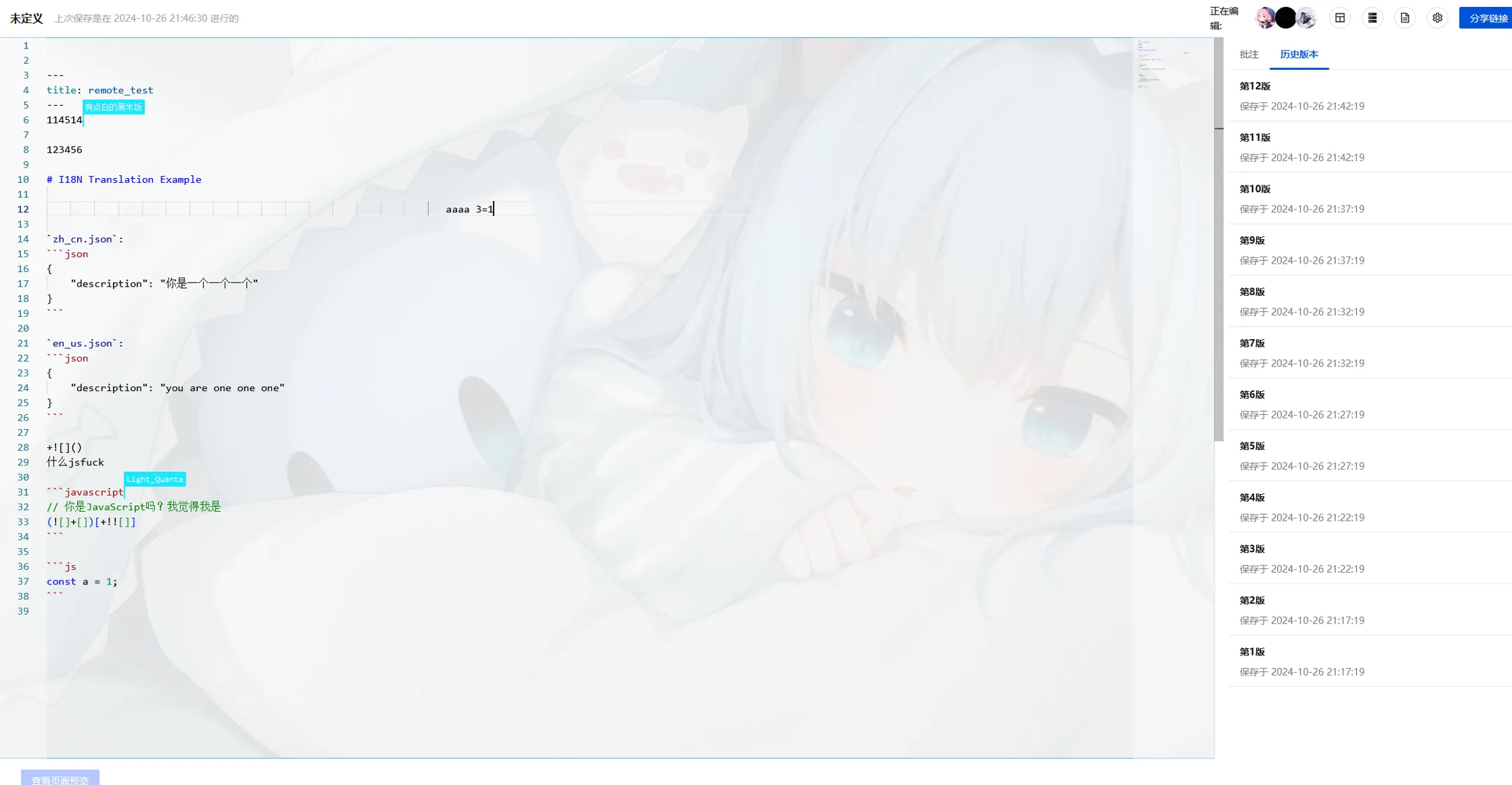
包含的功能如下:
- 多人编辑协同
- 提供协作者列表,光标位置信息
- 历史版本记录
- 支持不关闭浏览器的离线编辑,上线内容自动恢复
未来计划功能:
- 离线提醒
- 回滚操作发生后全体通知
- 浏览器关闭后内容恢复
接下来讲讲技术选型和一些小细节:
技术选型
参考过很多文章后我选择了 CRTD 作为冲突解决算法,其背后生态支持库是 Yjs,原因如下:
- 个人并不熟悉这个算法的过程,且项目存在隐性 ddl,时间成本较高
- 需要大量服务端编程,不清楚这个算法在后端是如何自动解决冲突的
- 本编辑器采用 monaco-editor 作为载体,社区中没有 OT 生态支持,很多代码可能都需要自己探索和自己写
- Yjs 包含一套完整生态,覆盖编辑器接入到通信协议实现,且各个部分之间都是单独仓库
- Yjs 对于 monaco 有一个简单 demo,与想象中的几乎一致
- OT 背后一个针对的方案是 ShareDB,但是数据模型的接口可能需要自己实现,且查看过一些基础代码后发现其编写的代码都相对底层,开发成本会偏高
- 项目中大部分词条字数最多是几千字,且为纯文本,而 CRTD 对于万字数量级的纯文本支持都非常好 (https://github.com/pubuzhixing8/awesome-collaboration/blob/master/crdt/5000x-faster-crdts-an-adventure-in-optimization.md)
当然现在看来两者都有各自的优劣,尤其是在离线后重连这一部分上,这一部分会放到后面展开讲讲
最小 Demo 实现
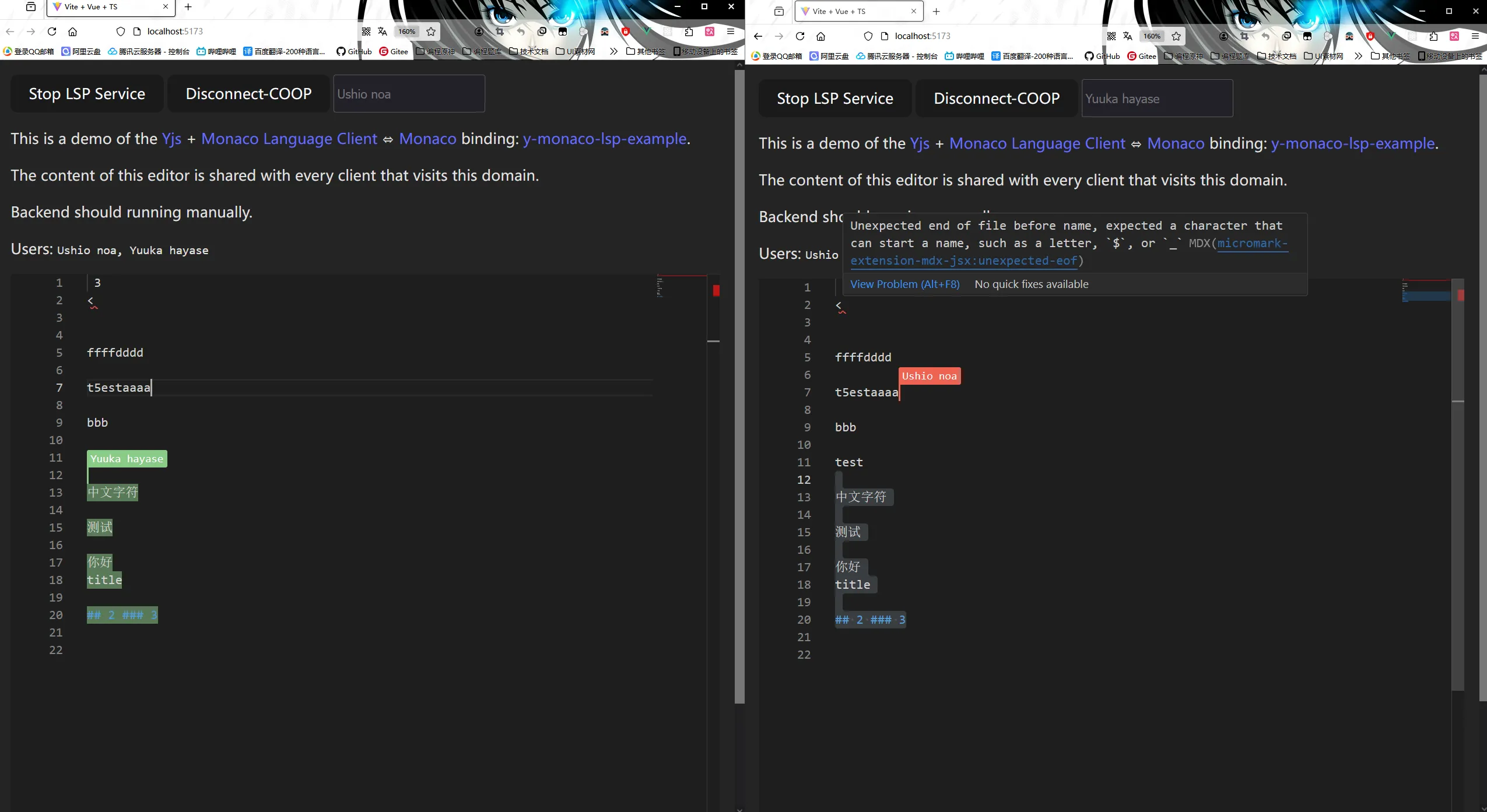
这是个人基于官方例子实现的一个符合项目需求的最小 Demo,前端是 monaco 实现,后端则是使用的 elysia + bun 实现的一个处理:(Y-LSP)[https://github.com/QingXia-Ela/y-monaco-lsp-example]
相比官方示例这里提供的额外功能是用户名字展示 + 悬浮。
这里还有一个额外功能是语言服务器服务,因为这个项目我们编写了一套基于 LSP 协议的 IDE 智能提示,用于在词条内给编写者提供提示,提升开发效率,其细节以后可以在另外的文章说说。LSP 与本文无关,可以忽略。
技术方案、架构与落地流程
技术方案只讲一下前端的: monaco-editor + yjs + y-websocket + y-monaco。
目前服务端架构图如下:
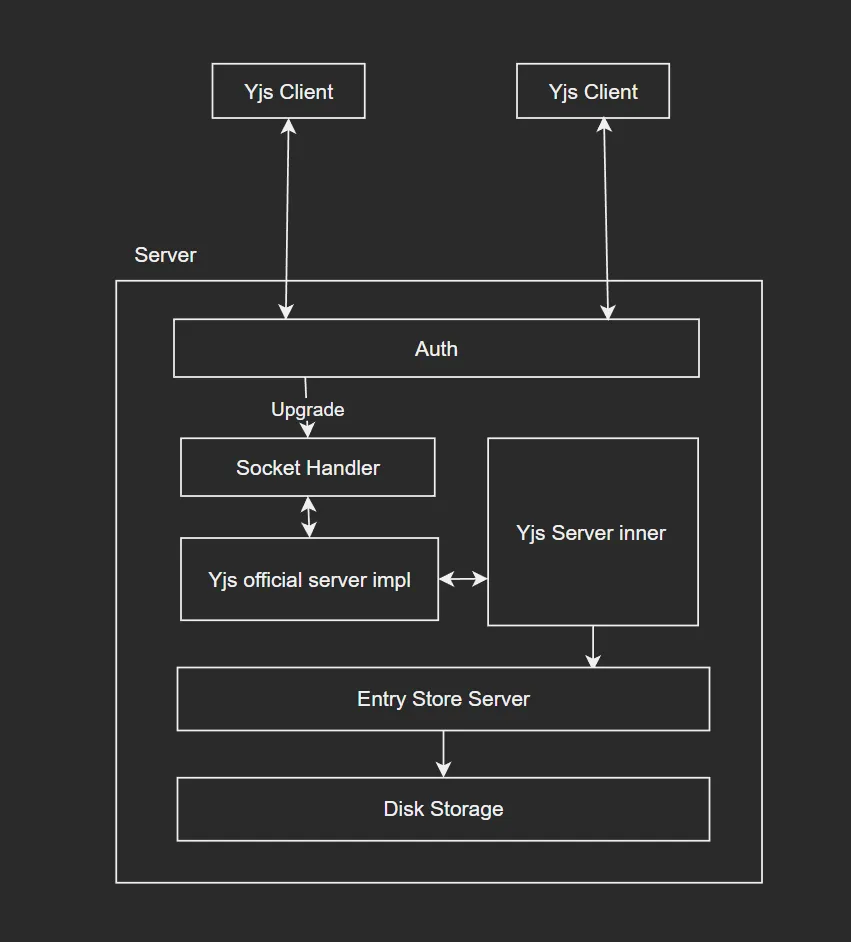
其中 auth 层在 tcp 升级为 websocket 前发挥作用,如果验证失败直接 deny。然后是 socket 层会实现一个到 y-websocket 服务端官方实现的一个转发,这个服务端本人经过了一定的改写,使得他在监听到共享数据发生变化时向最终的词条服务器发送发生变化的词条的内容,词条服务器实现保存到硬盘上的操作。
先讲一下具体落地的简单流程:
- 编写 Demo 确定架构与消息流程
- 移植官方实现的 Yjs Server 实现,并修改鉴权流程
- 处理历史版本保存实现,排查问题
- 上线,压力测试,拉上114个人,准备514份长文本,冲刺,冲刺,冲,冲,冲
- 循环 3-4 步,没有问题后发布并开始上线使用
一些已实现功能遇到的问题细节
历史版本
目前历史版本是通过完整记录词条文字实现的,回滚过程则是直接修改服务端 Yjs doc.getText().toJSON() 获取原文并存储内容到缓存实现。
这个操作会产生一个新的历史记录插入到历史记录队列顶部。
其次是几分钟保存一次的问题,本项目是当有人进入词条编辑房间时五分钟保存一次,当房间无人时关闭定时器。
未解决的问题在下方有写明
鉴权实现
Websocket 是基于 TCP 协议,其中将 TCP 连接升级为 Websocket 时是在请求头中携带 Connection: Upgrade; 与 Upgrade: websocket,随后连接升级为全双工通信,这个可以通过 node 原生 http 库中的 upgrade 事件进行监听,在 elysia 则是通过 parse 函数监听。
协同者光标
协同者光标的 css 需要自己写,且要进行动态插入,具体可以参考我写的 demo
中断恢复 - 客户端无持久化存储与初始内容
中断恢复是整个项目中最难处理的一个部分,这里的中断指的是客户端或者服务端关闭后重连,中断可分为以下3种:
- 客户端中断重连,服务端全程在线
- 客户端全程在线,服务端崩溃后重新上线
- 客户端中断重连,但是在中断期间服务端崩溃后重新上线
针对服务端崩溃的情况,其首先的影响是丢失了 Yjs 客户端连入上下文的信息(最后操作时间、删除集等),假如此时服务端恢复客户端重新连入后,服务端会把所有人内容都视为一个新插入,从而导致大量的内容重复。
而针对客户端中断的情况则分有上下文与无上下文的情况,有上下文的情况就好办,发生此类问题的场景是客户端断网,但是保存浏览器开启的状态,此时的恢复是可以依靠 CRTD 算法自动解决。
而丢失上下文的情况则是由于不可预期的故障导致客户端关闭浏览器时发生,但假如客户端没有实现持久化存储,这种情况则可以忽略,因为这相当于一个客户端从无状态情况下正常连接到服务端。
持久化存储的情况放在后文讨论。
目前实现的方案是服务端中断恢复时照常丢失上下文。服务端恢复后客户端重连时,客户端在接收到服务端同步内容后进行一次 diff 比较,对双方的变化均进行保留。
当然这种 merge 存在一个问题就是不能有多个客户端并发进行 merge 操作,否则可能会导致内容错误
客户端 merge 后导致的用户焦点不正确问题
该问题仅发生在服务端中断后客户端 merge 的行为上。
本项目采用的词条换行符为 \r\n,但是 yjs 的 toJSON 方法转换后的结果只保留了 \n 。所以在通过 monaco 方法设置值的时候要把所有换行符替换为 \r\n,否则会出现用户光标位置不正确的问题,从而导致用户看见的内容不一致。
挺可怕的一个问题,但是运气很好,试了一下一个个字符前进,然后就发现了每到换行符时,别的用户的视角发现操作的客户端并没有换行,而是停留在行尾部。
这种问题只会发生于纯文本应用。
未解决的问题与针对解决方案构思
历史版本
前文提到历史版本有个问题就是,用户的撤销栈没有同步清空,需要进行清理操作。
其次是内容大小,所有词条缓存都是存储在变量而不是外部如 redis 等,这就带来了个问题,万一开启房间多了或者某个词条特别长,都会把v8可怜的那点内存撑爆。未来肯定是要移动到外部存储去。
最后是保存的数据结构与持久化,Yjs 创造的快照是 Doc实例 + 用户状态/操作步骤记录向量
其中快照类源码如下:
export class Snapshot {
/**
* @param {DeleteSet} ds
* @param {Map<number,number>} sv state map
*/
constructor (ds, sv) {
/**
* @type {DeleteSet}
*/
this.ds = ds
/**
* State Map
* @type {Map<number,number>}
*/
this.sv = sv
}
}
此处我们不关心为什么 Yjs 只需要 DeleteSet 即可实现快照存储,且他只存储用户对文本的操作,而不存储原文。我们只需要知道他能根据 DeleteSet 恢复内容即可,这里也是后续规划服务端中断掉线后恢复的必要点。
针对本项目我个人还是更倾向于直接存储词条原文,因为其体积并不是很大,可能一个词条文件 10KB 就是上限了,且相比快照恢复,字符串的运行时开销会更小点?
但是面对大文件或数据结构复杂文件,我还是更推荐使用快照功能,虽然从快照恢复内容仍然需要源 yDoc 对象,具体看:探秘前端 CRDT 实时协作库 Yjs 工程实现 - 回溯历史记录一段。
这篇文章讲的也很不错,揭示了很多底层细节。此处我们只关注这一段提到的 DeleteSet 非常轻量的部分,引用原文内容:
由于 DeleteSet 的结构非常轻(例如在记录了真实用户 LaTeX 论文编辑过程的 B4 benchmark 数据集中,18.2 万次插入和 7.7 万次删除后仅生成了 4.5KB 的 DeleteSet),这种设计就进一步贴近了「零开销抽象」,因为删除时并没有创造出任何未知的新数据。
按大文件的体量相比,额外的几KB的DeleteSet序列化存储似乎不算什么。
而从业务开发速度的角度来看,这套逻辑是可以复用到下文的服务端中断恢复的。
如果要实现快照恢复则还需要研究 yDoc 对象序列化存储至硬盘,这个又是一个新的领域了。
客户端持久化存储
Yjs 同样也提供了内容持久化的存储服务,可以通过 y-indexeddb 来实现。
但是本项目一直没有启用的原因是:假如因为意外导致浏览器上下文丢失后客户端重新打开页面并进行了内容编辑,此时客户端仅剩下一套内容,且可能与服务端存在差异。
针对本项目,此时我更偏向于向用户提示说版本与服务器有冲突,让用户自行选择保存哪一份副本,或将用户的副本临时存储到其个人空间。
而针对更大型保障能力需要更强的项目,且在有研发团队的支撑下,我会实现一个更好的方案:
- 客户端进入编辑状态时会将ID存储到本地中
- 客户端在编辑时会将自己的操作与状态序列化存储到本地
- 服务端在发现客户端离线后为其保持 2 小时的状态存储,或将其放入外存以减少内存占用。否则当客户端重连时进入版本与服务器冲突处理流程
- 客户端恢复连接后与服务端进行 CRTD 同步
解决方案的本质是尽量恢复完整的上下文,做到类似于客户端在有上下文的情况下重连进入服务器。
服务端中断服务后恢复
接着上面的中断恢复,结合前文提到的快照来说一下未来设想的解决方案。
本流程是基于目前已有基础建设提出,后文还会提到一个新的后端一站式建设方案,对于那个方案可能还会提出一个新的流程
- 客户端首次连入时向服务端请求一个ID
- 服务端每隔 1 分钟保存一次快照 + 每次修改后节流一段时间再保存快照(源 ydoc 对象序列化 + yjs 快照创建方法,转为可存储在硬盘或数据库的内容)
- 客户端主动离线时,清理其信息;客户端非主动离线时,服务端为其保留 2 小时上下文
- 客户端恢复后,若超过了两小时,则将用户内容储存进用户的副本空间中
然后说一下目前 merge 存在的问题:
-
多个客户端同时进行 merge 时导致内容读写位置错误 这个属于并发冲突的问题,解决方案是监听 socket 信息,多个客户端连入必须排队进入且在前一个客户端完成 merge 操作后才能进入下一步,在后端上具体实现就是如果发现前一个连入 socket 完成同步消息传递后就开放下一个进来。这里可以通过 promise 实现顺序连入,当然你还要搞懂 yjs socket 底层传输的二进制信息就是了。
假如说不进行控制的话那么就会有脏路径读写的问题存在,从而导致文档混乱。
-
merge 行为发生后用户焦点会丢失 这个问题与 PingCode 情况一样,都是因为光标是根据文字相关位置确定的,merge 操作相当于重新复制粘贴了一大段内容,而之前用户相关的位置的信息就丢失了,因此导致 merge 发生的时候用户焦点会回到编辑器顶部。
可能的优化方案是 diff 算法不使用 setValue 方法以避免全量替换,取而代之的是使用 monaco 的 applyEdits 实现按需增删,避免焦点丢失;又或者记录用户的 offset 位置,当 merge 发生后自动移动光标到原来的位置。
undos/redos
这里的是依赖 monaco 的本地操作栈记录,但是这个会存在脏路径读写问题,比如用户1插入了文字 这是一段待插入的文字,然后用户2在中间插入了 增加内容,此时假设内容变成了 这是一段待插入增加内容的文字
而由于 y-monaco connector 并没有实现与 Yjs 的操作栈结合,所以 monaco 在撤销时是基于用户自己的操作,针对上面那段文字,Monaco 会认为用户在某一行中某个位置添加了 10 个字,因此撤销操作变成了从这一行的那个位置移除 10 个字,此时用户1撤销后就变成了 容的文字,用户 2 的文字被移除,但期望结果应该是保留用户 2 的输入,即 增加内容。所以未来需要使用 Yjs UndoManager 去实现无脏路径撤销。
与 PingCode Wiki 对比遇到的问题
PingCode 问题总结: https://github.com/pubuzhixing8/awesome-collaboration/blob/master/crdt/yjs/yjs-fqa.md
中文输入中断
这个问题也同样发生在 monaco 编辑器中,在同一行中的中文输入内可以观察到中文输入的内容也会进入 monaco 编辑器并进行远程同步。后续将会进行问题研究与修复。
一个可能想到的解决方法是,控制 monaco 在发现中文输入或其他语言输入时,不将拼音给同步到编辑器内;或者对用户输入操作进行节流,直到用户停止输入后才将本地输入向服务器同步?
焦点不正确
这个问题在 monaco 中没有发生,可能是因为 monaco 是纯文本应用,面对换行操作时在底层数据结构采用的是 insert 一个换行符,从而保证相对位置仍然正确。
点击聚焦 - 光标闪烁后跳动到原来的位置
这个在 monaco 中实测没有发生,因为用户移动光标的信息会立马同步到其他客户端,没有节流,当然这也导致了在连续移动光标时大量消息发生了传输,未来肯定是要对这个操作节流的。不过不同于 slate,远程选区操作不会影响到内容的插入与删除,因为 y-monaco 在远程用户选区上只是渲染出用户选了哪一部分,而不会影响到编辑器本地内容选择。
分布式系统与异地容灾?
虽然没实践过,但是我觉得可以想象一下架构的样子:
由于 Yjs 天生就是无中心的数据冲突解决的具体实现,在不考虑服务端上下文永久保存的情况下可以实现一个星型的异地多活图,其中中心机房是任何一个可能的 Yjs 服务端(即本项目后端),然后服务端之间的 Yjs 服务端实例通过机房间专线 + 定制的通信协议与中心机房通信,此时仅保证有一个机房在跟词条服务器进行读写操作。 假如中心机房挂了,可以立刻选一个新机房作为中心机房,保持业务不中断。同理词条服务器也可以改进为分布式系统,但是这个不在本文讨论范围内。
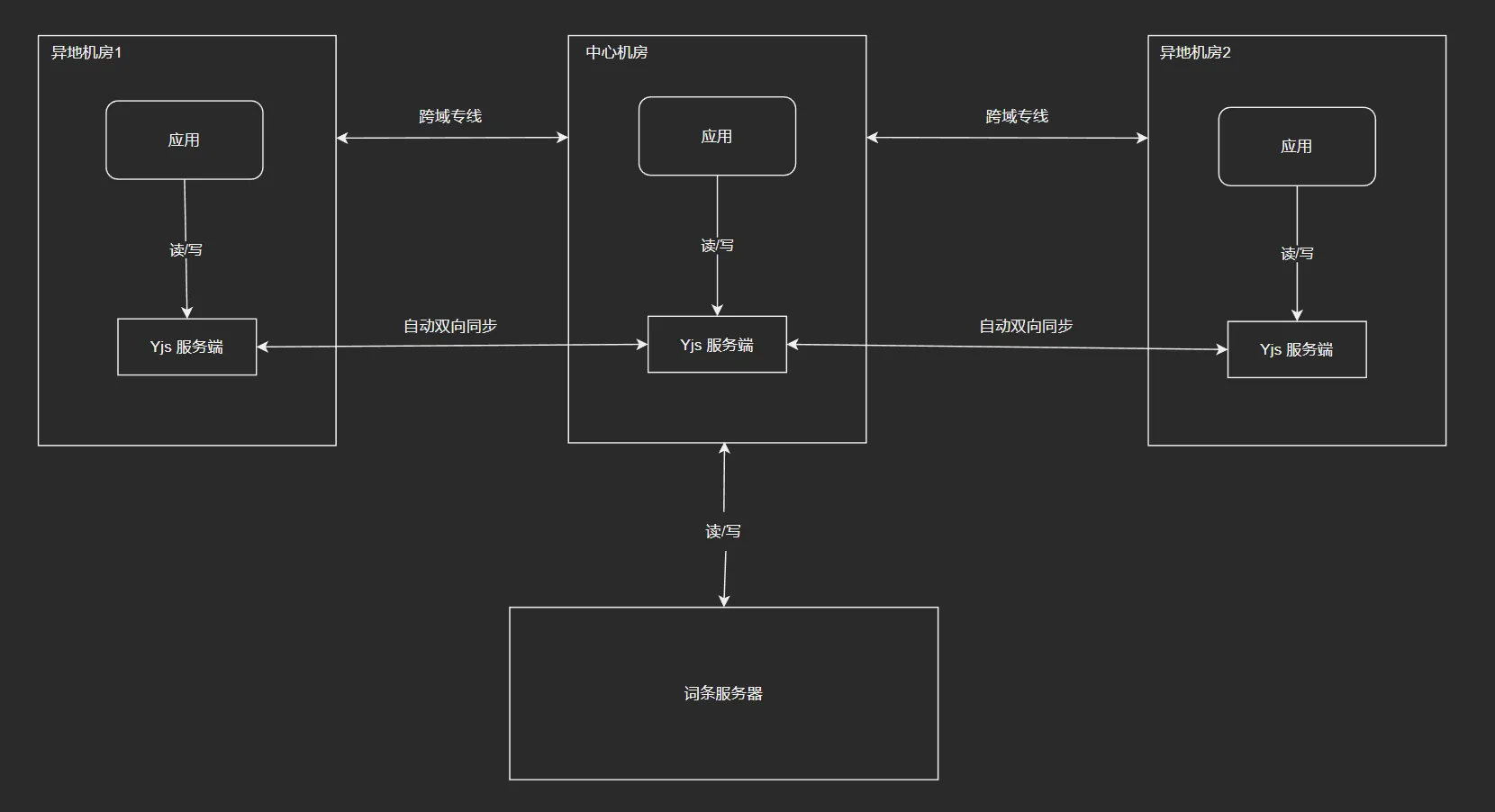
来源:https://www.bilibili.com/video/BV18v411c7FX
有没有更好的后端一站式解决方案?
有。 链接地址: https://tiptap.dev/docs/hocuspocus/provider/introduction
为什么项目不使用?因为早期调研时忽略了资料搜索,这个是看 b 站某个视频的时候看到评论说的一个玩意,光是看介绍就发现这玩意满足的需求还挺多的,包括但不限于只读,中断恢复,数据库,redis,权限验证等。
为什么不移植?因为这是项目临近上线时才发现的,只能说很可惜,然后预估了一下要改写的代码,量还不少(将所有Provider替换成该包专属的,整个socket转发流程都要改写),因为整个协议底层都改了。只能说路还很长。
总结与反思
从最开始的技术选型到 CRTD 应用落地,这中间前前后后大约也有近四个月,而且效果并不是很理想,因为其中还穿插了一个语言服务器的支持,假如没有考虑语言服务器那么这些顶多两个月就能实现完成。
为什么最初是直接考虑 Yjs?因为看到 PingCode 有技术落地实现,且有一些详细的文章参考与细节修复;其次是 Yjs 生态,天然支持 monaco,且网络上还不少解析 Yjs 的文章。但最后回头看过来我觉得我选择 Yjs 的时候还是少考虑了一些问题:
- 没有现成的生产级别投入使用的开源代码可以参考,必须要自己一点点排查可能遇到的问题
- 看到 Yjs 进行了无脑选择,而不是再找找 OT 相关生态(虽然选择 Yjs 可以帮助更快落地,因为很多库可以直接现成使用)
- 在 Yjs demo 编写过程中强行插入 LSP 开发,把一些可能很早就完成的尝试给拖到后期才一起完成
- 没有考虑自己的应用场景,没有尝试过在纯文本场景下将 CRTD 和 OT 进行优势对比与实现难易估计
实践是检验真理的唯一标准,这句话是一点错都没有。从最开始满心欢喜的选择 Yjs 以为项目可以快速落地,再到发现 Yjs 并没有针对服务端中断实现一个处理过程,再然后就是排查各种奇怪的问题,最后还要考虑新功能的快速集成实现。这么多内容放在一篇文章里肯定是没法彻底讲清楚的,所以我挑了一些有代表性和需要紧急修复的情况来谈。 但最终我还是要感谢这些框架的作者,这里用到的大部分基础代码与相关技术几乎都是开源的,我的内心其实是非常佩服这些开源作品的贡献者的,同时也在督促自己努力的去做更多的开源输出。假如只扔给我一篇 CRTD 或者 OT 的论文让我自己用 js 实现出来一个前后端交互实现,那怕不是这个远程协同的设想直接胎死腹中。
假如可以回档?
假如能够回档的话,首先就是先把 LSP 放一下,然后直接针对 CRTD 和 OT 各写一个 demo,搭配上必要的中间件如权限验证、排队、同账号多客户端连入、服务中断等。这里的每个中间部分可能都因为算法的不同而有不同的实现方法。
评估一个月后确定好最终技术栈,并投入实现,然后就是如上文的测试。
参考资料
- https://github.com/pubuzhixing8/awesome-collaboration PingCode 实现协同时的问题收集
- https://juejin.cn/post/7077092715409702925?from=search-suggest 多人协同编辑技术的演进
- https://zhuanlan.zhihu.com/p/452980520 探秘前端 CRDT 实时协作库 Yjs 工程实现
- https://segmentfault.com/a/1190000041023337 PingCode Wiki 技术揭秘
- https://juejin.cn/post/7074092429862764575 如何解决多人编辑场景下的内容覆盖问题